
Engineered For Enterprises
Optimize your data operations with feature-rich, enterprise-grade platform, designed to meet the needs of your enterprise and support NFRs.
.png)
Multi-Cluster
Supports business to scale pipelines beyond the cluster limit and ensuring geo-redundancy and high availability at the same time

Cloud Agnostic
The Solution is designed to run on public clouds like AWS, Azure and GCP as well as private cloud data center.

SSO & Security
With built in security capabilities that meet industry standards, ensuring that your data is protected to the highest degree.

Data into action
Unleash the power of distributed processing powered by Apache spark into your data pipelines to manage data at scale

Data Governence
Easily manage and govern your data with automated tracking and customizable rules and take complete control over your data pipeline.
.png)
Optimization
keeping track of your capacity and conflicts, advanced optimization recommendations to maximize efficiency and cost savings.
Take Data Engineering at next level
Streamline your data operations and Unleash the full potential of your data to drive business growth with a powerful solution.
Data Integration
Enriched with exhaustive list of industry popular no-code connectors & prebuilt templates for data stores, quickly automate and streamline your data integrations. Improve visibility & data accuracy with fully automated platform that offers easily defined SLAs, data governance.
Read More >>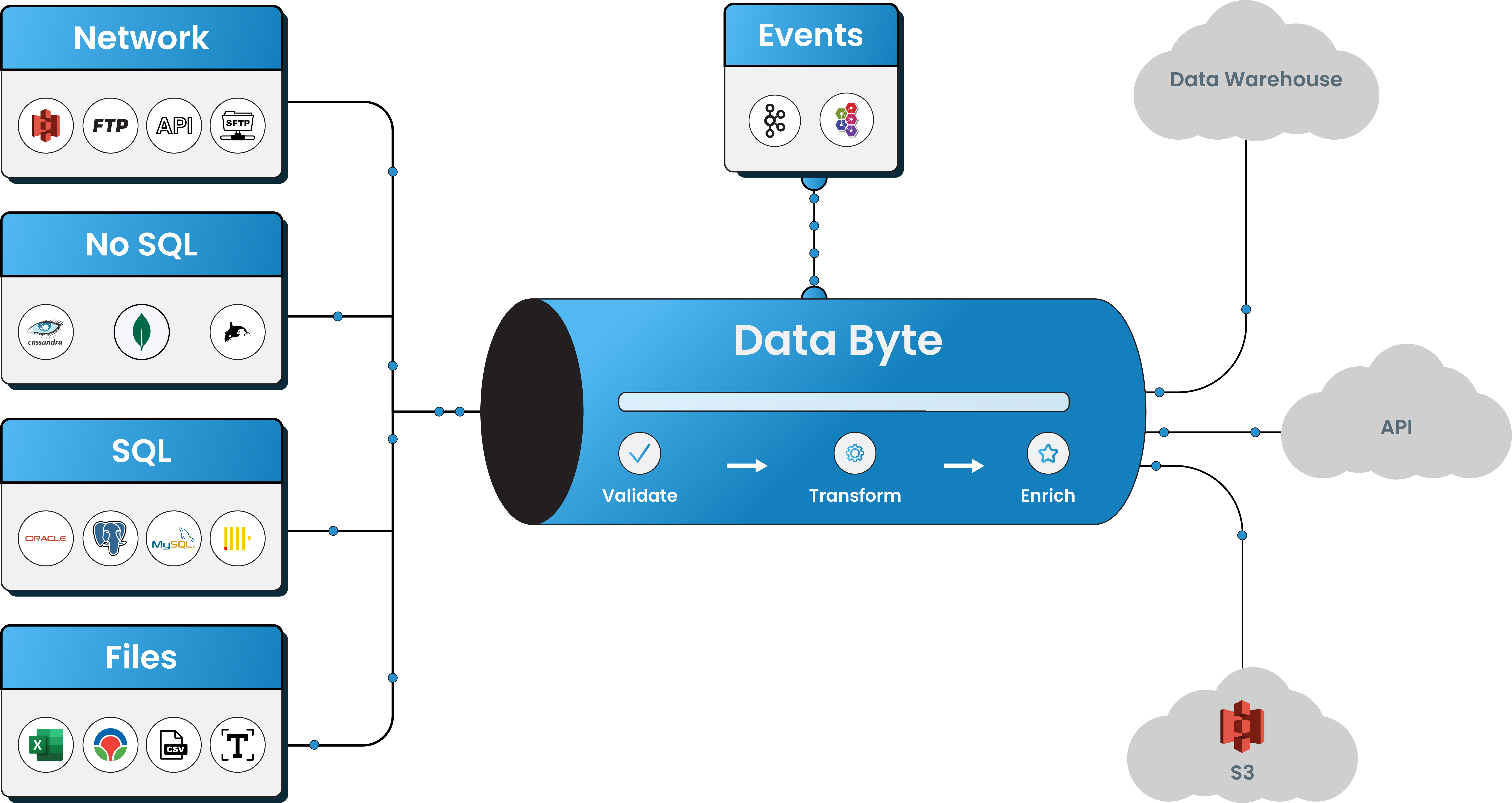
Change data capture
Change & Heavy data replication Data is fundamental to every enterprise. DataByte, manage and track data changes efficiently and in real-time with advanced CDC capabilities and comprehensive data integration solution. Variety of data sources are supported for CDC solution.
Read More >>
Advance ETL
Platform with Intuitive user interface having variety of no-code connectors for seamless pipeline design with prebuild pipelines. Achieve operational excellence with comprehensive suite of reliability features, including continuous data validation, error management, automated monitoring and notifications, and built-in retry mechanisms.
Read More >>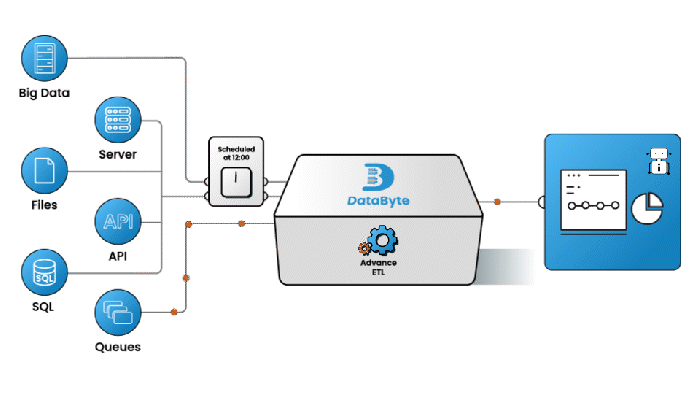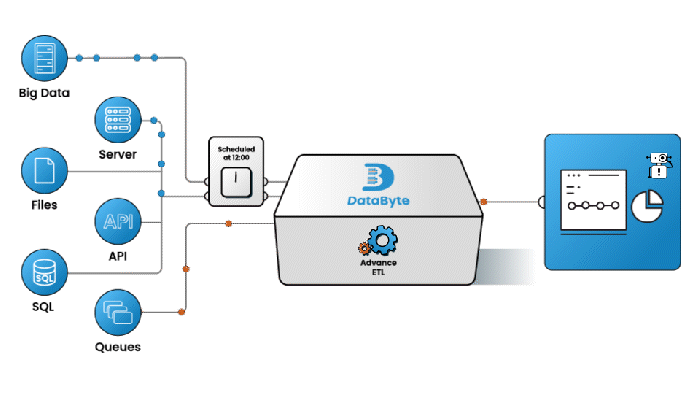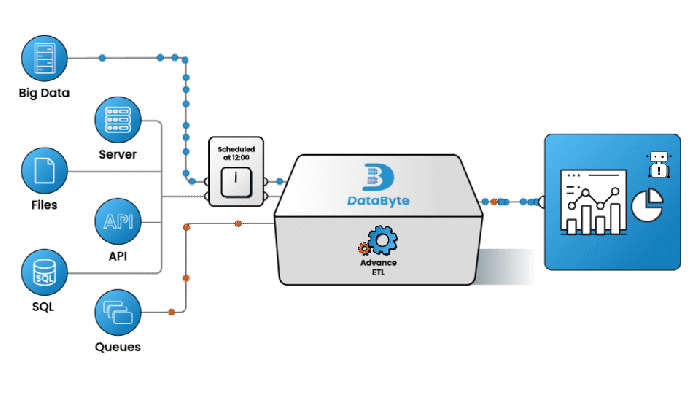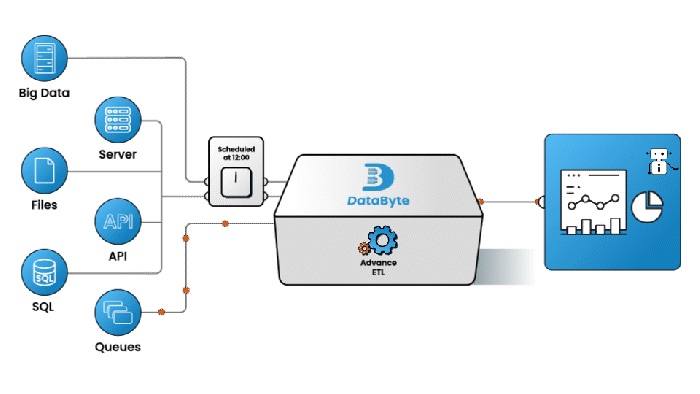
SparkOps
Platform offers seemless integration of Apache Spark and offeres a unifed, cloud-based Spark management platform name "SparkOps" to Leverage the power of Spark with unified drag & drop interface to design advance pipelines and witness the power of distributed transformation capabilities by easily scaling pipelines for your big data usecases.
Read More >>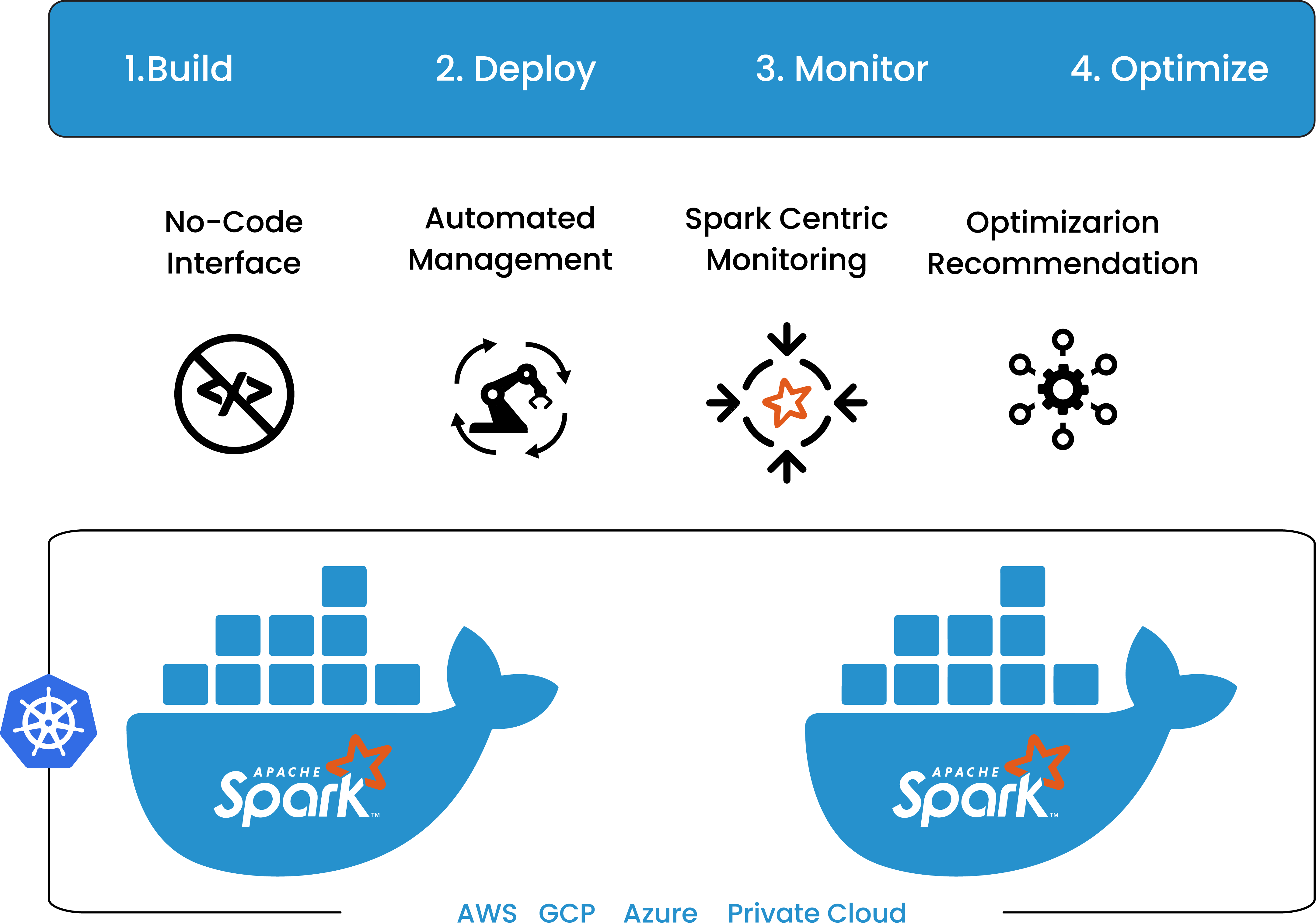
Algorithm
Algorithm builder allows you to define rules and actions based on business data and take realtime business decisions. By integrating these rules and actions into your data pipelines, you can continuously monitor your business data and take informed, automated actions based on that.
Read More >>
Advance Analytics
Easily understand your data with our advanced analytics and customizable dashboards. Create and share professional reports with your team to make data-driven decisions. Platform gives you the flexibility and control to analyze your data in the most meaningful way.
Read More >>
Intellisense
Optimize your data pipeline with our Intellisense product. The built-in recommendation engine analyzes pipeline execution and suggests performance optimizations along with recommendations for resource allocation to increase efficiency and reduce costs.
Read More >>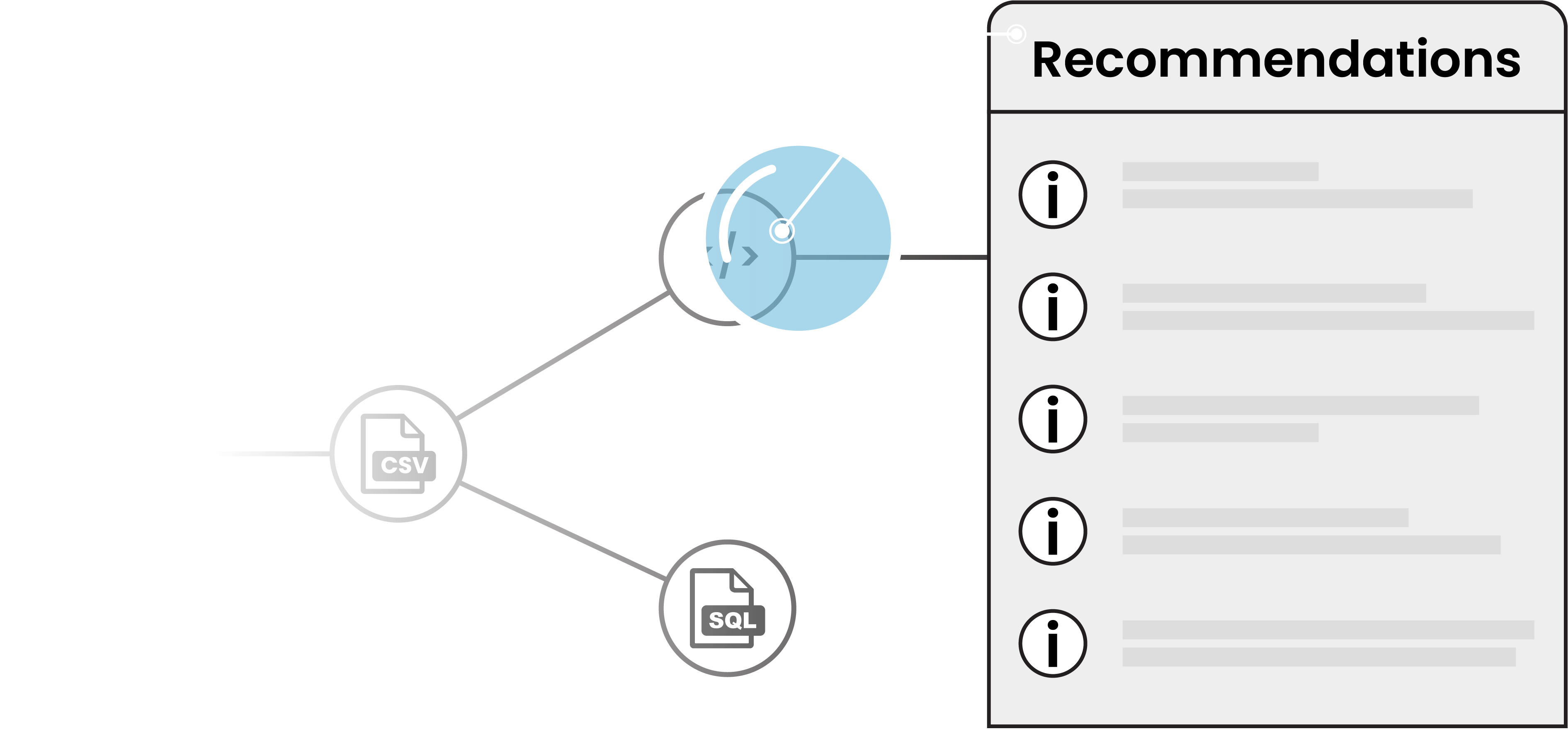
Frequently Asked Questions
Yes. Platform is cloud native and supports variety of clouds. You can choose the cloud strategy that best chooses you - Your Private Cloud, Any of popular Public clouds (AWS,GCP,Azure) or any hybrid clouds .
Solution supports a wide range of sources and destinations, including both structured and unstructured data. Some examples of the types of sources and destinations that our platform supports include:
- Relational databases (e.g. MySQL, PostgreSQL, Oracle,ClickHouse)
- NoSQL databases (e.g. MongoDB, Cassandra,Hbase)
- Data warehouses (e.g. Redshift, BigQuery)
- Cloud storage (e.g. S3, Azure Blob Storage)
- Flat files (e.g. CSV, JSON,Parquet)
- Message brokers (e.g. Kafka, RabbitMQ)
We are continually adding support for new connectors, explore our detailed library.
Our platform's CDC capabilities allow it to detect and capture data changes made to a variety of sources, including relational databases and message brokers. Once the changes have been captured, they can be processed and transformed as needed before being loaded into the desired destination. This enables our platform to support real-time data integration and synchronization across systems, helping you to manage and maintain up-to-date data.
Yes. ETL chaining is a very useful feature platform offers. You can link multiple pipelines to be triggered sequently or in parallel to achieve seem-less orchestration across your data journey. Another advantage is that it allows you to create reusable transformation pipelines and utilize them as and when needed
The inbuilt observability layer provides a range of tools and features that enable you to monitor the
status and performance of your pipelines in real-time, identify issues and bottlenecks, and take
corrective action as needed.
Some examples of the types of data and metrics that our observability layer can provide include:
- Pipeline execution times and performance metrics
- Data quality and integrity checks
- Error logs and stack traces
- Resource utilization and resource allocation
- Custom metrics and alerts
- By providing this level of visibility into your data pipelines, our observability layer helps you ensure that they are running smoothly and efficiently, and helps you identify and address any issues that might arise. This enables you to get the most value out of your data and make more informed decisions based on the insights you uncover.
Our unified data engineering platform has been designed to be user-friendly, with an intuitive interface and a range of tools and features that make it easy to use, even for users without technical expertise.
- A drag-and-drop interface for building and managing ETL pipelines
- A wide range of pre-built connectors and transformation functions that allow users to quickly and easily extract, transform, and load data
- A range of visualization tools and dashboards that make it easy to view and understand data trends and patterns
- Context-sensitive help and documentation that makes it easy for users to learn and get assistance as needed
- Overall, our platform has been designed to make it easy for users of all skill levels to get up and running quickly, and to be productive with minimal training or technical expertise. This makes it a great choice for organizations looking to streamline their data engineering processes and get more value out of their data.
Apache Spark is a powerful open-source data processing engine that is widely used for large-scale data processing and analysis. In our unified data engineering platform, Apache Spark is used as the transformation engine, which means that it is responsible for performing the data transformation and processing tasks that are required to move data from sources to destinations.
Some examples of the types of transformation tasks that Apache Spark can perform include:
- Data cleansing and formatting
- Aggregation and summarization
- Joining and merging data sets
- Applying custom transformation functions
- Enriching data with additional information
- Apache Spark is designed to be fast and efficient, making it well-suited for handling large volumes of data and performing complex data processing tasks. Its distributed architecture also makes it highly scalable, allowing it to handle increasing data volumes and workloads with ease.
Our unified data engineering platform has been designed to handle large scale and multi-cluster environments, making it a suitable choice for enterprise-level deployments. The platform is capable to orchestrate the pipeline on different k8s clusters that ensure high availability and geo redundancy at same time also enabling it to efficiently distribute data processing tasks across multiple clusters. This ensures that our platform can effectively handle the demands of even the largest and most complex data engineering projects.