Connect Widely used
Data Sources effortlessly
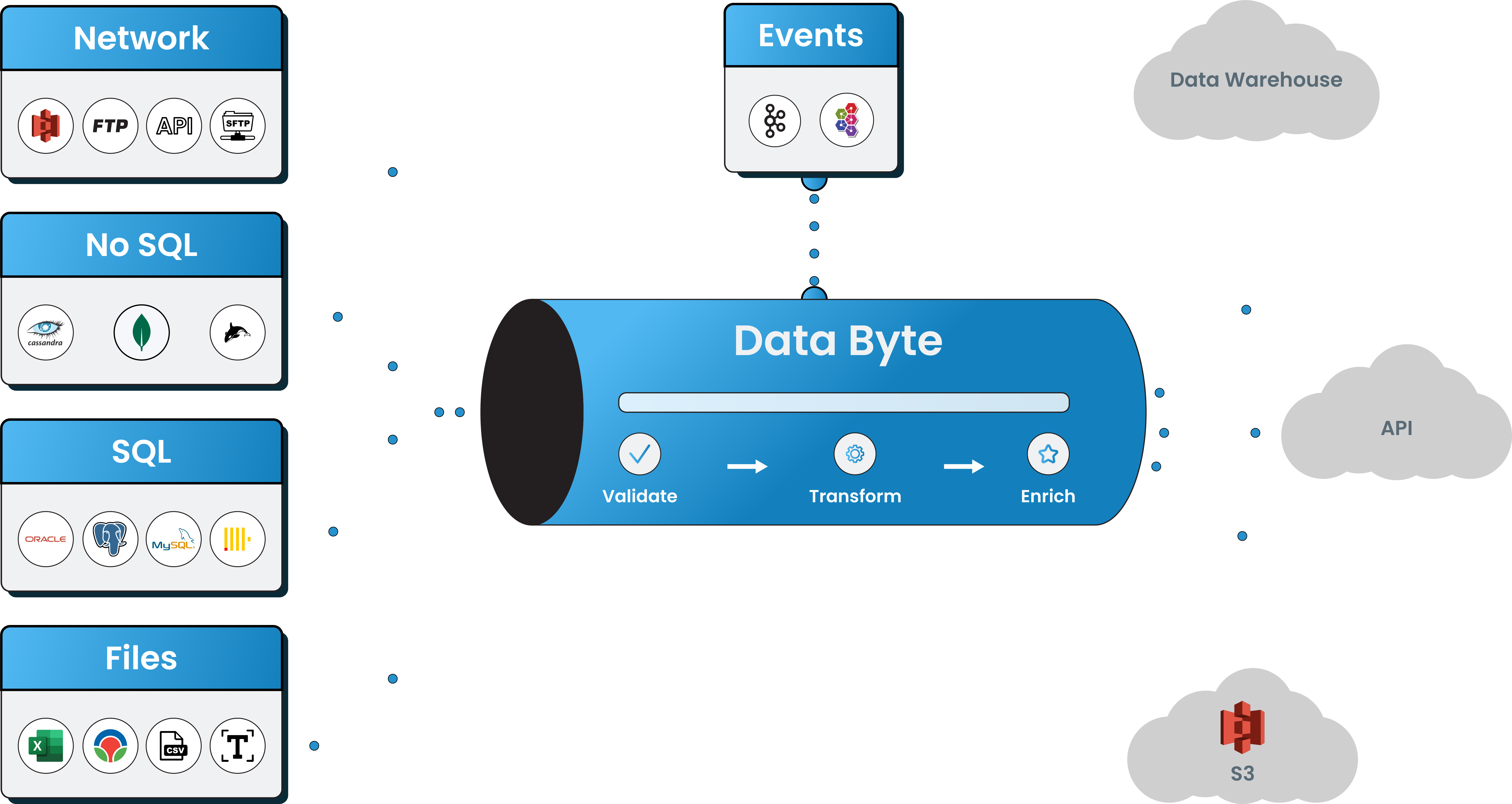
Say goodbye to complex data integration processes and hello to seamless, efficient data flow with DataByte. Widely used source and destination connectors available.

Intuitive UI to create
Pipelines in minutes.
User-friendly and configuration-driven interface allows you to create and manage pipelines quickly and easily.set up CDC pipelines in minutes.
Unified Integration
Layer for Partners
Unified Integration Layer provides a central platform for connecting to any data source, enabling enterprises to easily share data with their partners at scale.
Universal Connectors
Enriched with exhaustive list of industry popular no-code connectors & prebuilt templates for data stores, quickly automate and streamline your data integrations. Improve visibility & data accuracy with fully automated platform that offers easily defined SLAs, data governance.

Big Data Integration
DataByte's powerful big data integration capabilities allow you to easily connect to, extract, and transform large volumes of data from a variety of sources, all while leveraging the power of Apache Spark's distributed processing capabilities.
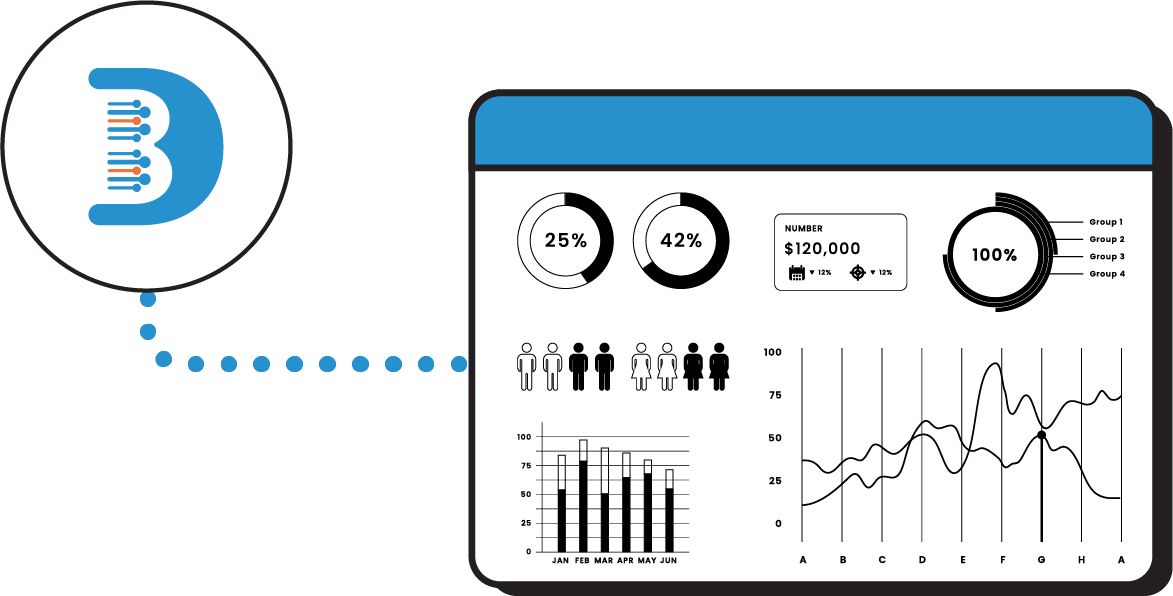
Real Time Insights
Platform's real-time insights capabilities allow you to stay on top of your data as it streams in, providing up-to-the-minute insights and enabling you to react quickly to changing circumstances.Expereince the unique power of Visual query and Data plotter component.
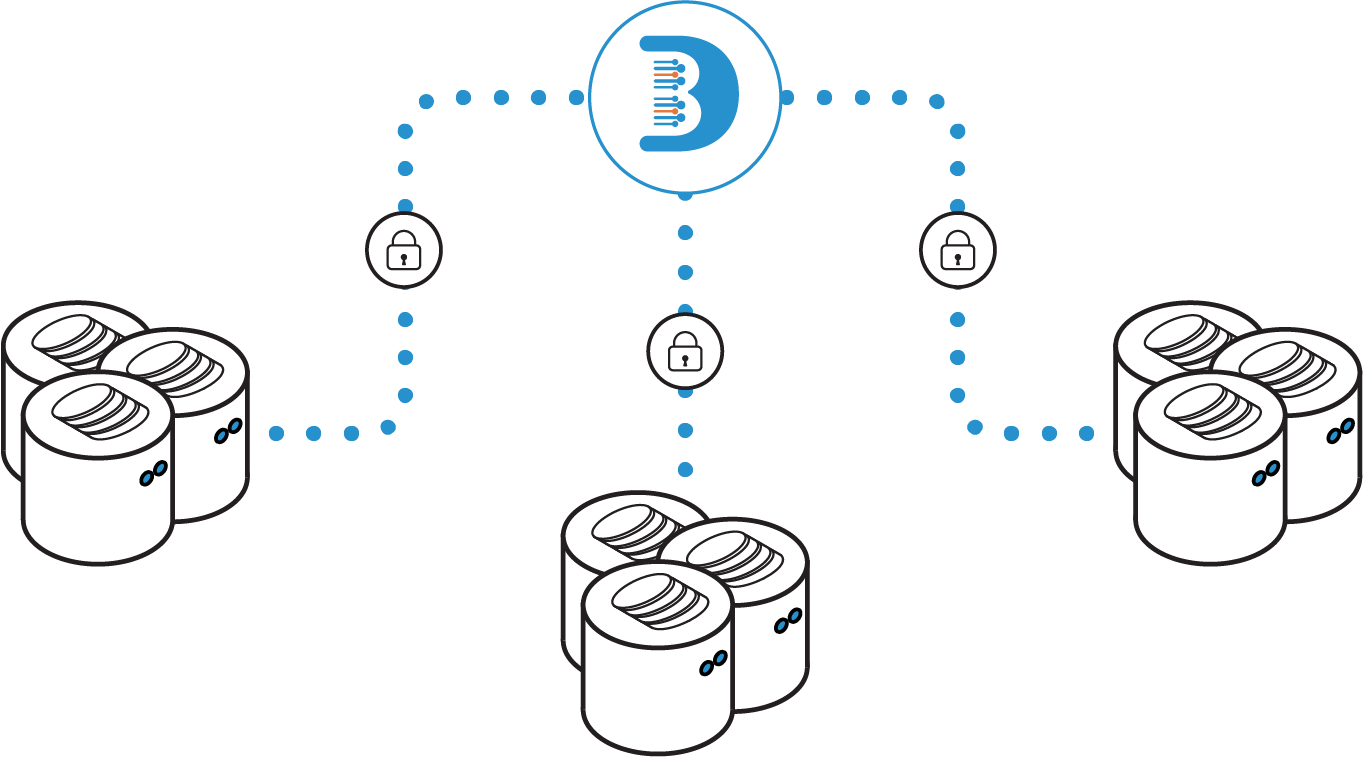
Isolated Security
The solution leverages Kubernetes to run pipeline as a container that enables full isolation of the data pipelines and esures that the data movement and processing runs in a secure, self-contained environment.
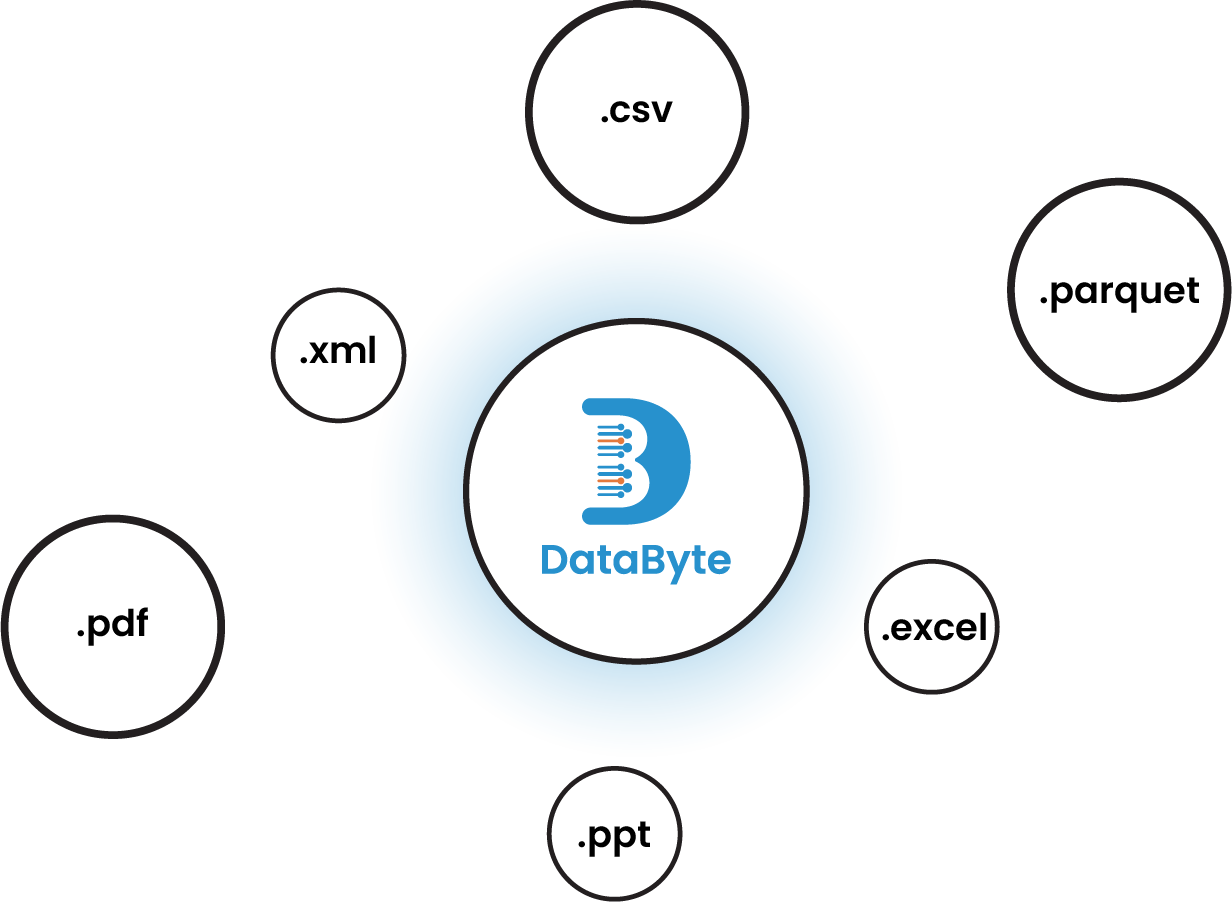
Variety of File Format
Files are one of the most effective and efficient ways to move big amounts of data. Platform provides a method to support it, no matter how you obtain your files. Supported The most popular file sources like FTP, SFTP, FTPS, S3, HDFS, and accepts a variety of file formats, including Excel, CSV, Delimited text, AVRO, Parquet, JSON, XML, ORC and more.
Frequently Asked Questions
The platform supports a wide variety of data sources, including popular relational databases (such as MySQL, Oracle, and SQL Server), NoSQL databases (such as MongoDB and Cassandra), cloud storage platforms (such as Amazon S3 and Google Cloud Storage), and file formats (such as CSV, JSON, and Parquet).
Yes, the platform uses Apache Spark on Kubernetes to process large volumes of data, making it highly scalable and able to handle even the biggest data sets.
Yes, the platform provides data governance features such as audit, balancing, control, data integrity and SLA.
The platform can be integrated with other systems in an enterprise through its various supported connectors and APIs. These include connectors for popular data storage systems and APIs for integrating with other enterprise systems such as ERP, CRM, and more. Additionally, the platform also supports custom connectors, allowing for integration with any system that has a data API.
Let's Talk
"Thank you for visiting our website!
If you can't find the answer you're looking for,please don't hesitate to
reach out to us using hte
contact infpormation above.
We look forward to hearing from you!"
if you have any question for would like to get in touch with us.you can
reach us using the following contact information :.
-
+91-0731-4280739
- info@bootnext.biz
-
195,Scheme No 78 part II\ Vijay Nagar,
Indore, India 452010